Secrets of Continuous ML Training in Production
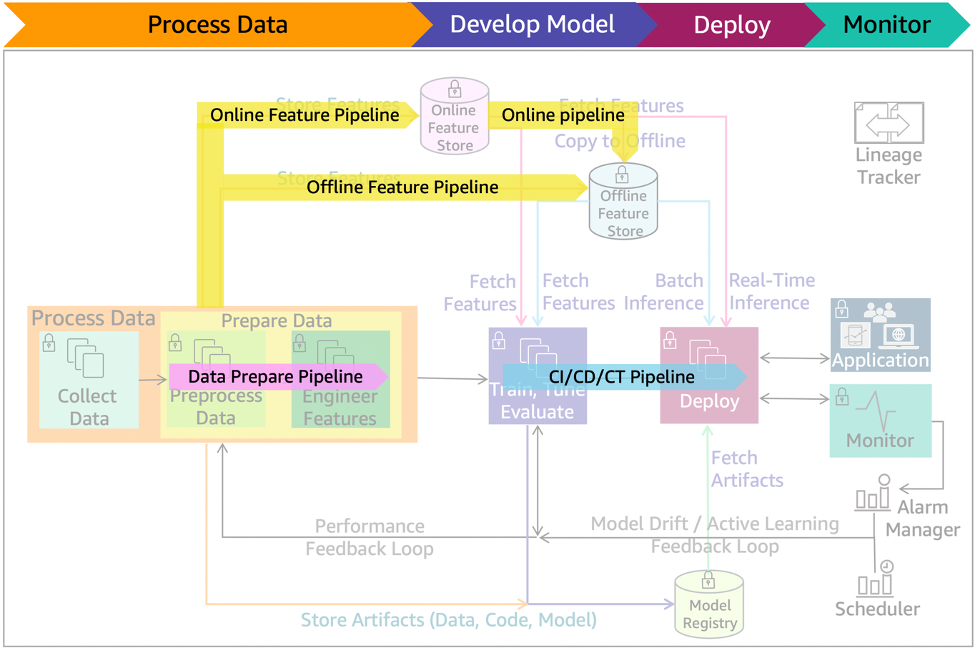
Yet Another Perspective on Continuous ML Training in Production
Machine Learning (ML) has revolutionized how we approach problems in industries ranging from healthcare to finance, retail, and beyond. However, getting ML models to work in production—the real-world environment where they interact with live data and users—can be tricky. Continuous ML training is one of the most crucial aspects of keeping these models accurate and effective over time.
In this article, we’ll break down the concept of continuous ML training in production, and explore why it’s essential, how it works, and what secrets need to know to make it successful, even if one is new to this area.
What is Continuous ML Training?
Before diving into the “secrets,” let’s clarify what continuous ML training means.
In simple terms, continuous training refers to the ongoing process of updating and retraining a machine learning model with new data. In production systems, models are deployed to make predictions based on historical data. However, over time, the data and patterns can change, leading to model drift (when the model starts underperforming because the data has changed).
Continuous training helps avoid this by ensuring that the models learn and adapt as new data comes in. It’s like keeping a software system up-to-date with regular patches, except here the “patches” are model updates based on fresh data.
Why Is Continuous ML Training Important?
Imagine an online store, and the recommendation system suggests products to customers based on their previous shopping history. Over time, customer preferences change—new trends emerge, people buy different products, and the shopping habits evolve. If the model isn’t updated regularly, it will keep suggesting old or irrelevant products, and users will have a bad experience.
Here are key reasons why continuous training is essential:
- Adapting to New Data: Real-world data constantly changes, and to maintain relevance, models must be updated to reflect these changes.
- Improving Model Accuracy: Regularly retrained models can identify and learn from new patterns in the data, improving their accuracy and reliability.
- Avoiding Model Drift: Without continuous updates, models can “drift” away from optimal performance as data changes over time.
- Better Decision-Making: Continuous learning leads to better insights and recommendations, directly affecting the quality of decisions made by the model.
The Secrets ….
Let’s explore the secrets of building an effective continuous training system for ML in production:
1. Monitor The Model’s Performance in Real-Time
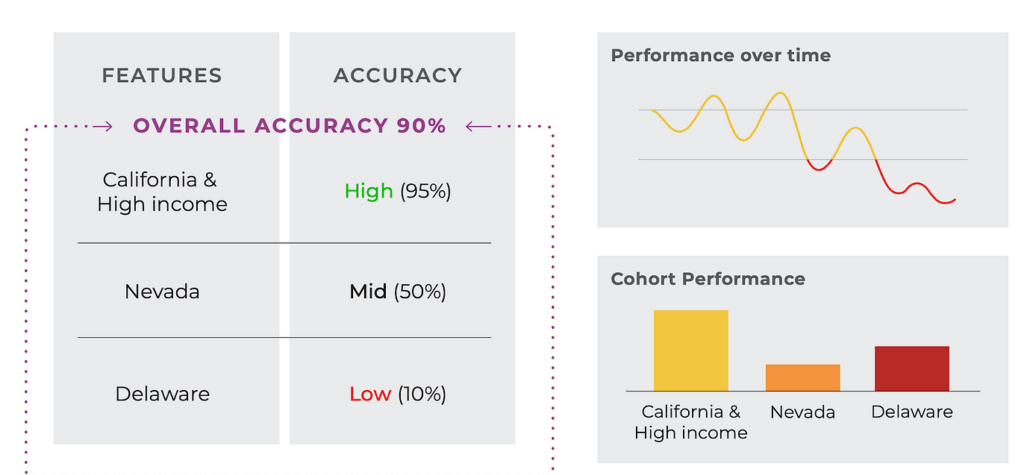
In production, the model is working with live data, and need to continuously keep an eye on how it’s performing. Imagine driving a car: the driver wouldn’t just set the wheel and forget it. Rather, constantly adjust based on what’s happening around you.
How to Monitor:
- Track key performance metrics: Accuracy, precision, recall, F1 score, etc. These metrics will show how well the model is performing.
- Use monitoring tools like Prometheus, Grafana, or Evidently to visualize how well the model is behaving over time.
- Business impact metrics: It’s important to connect model performance with real-world outcomes. For example, in an e-commerce application, track how the recommendation system impacts sales or customer engagement.
Secret Tip: Set up real-time alerts so that if the model performance drops below a threshold (say, accuracy falls below 80%), it triggers a retraining or debugging process.
2. Detect Model and Data Drift
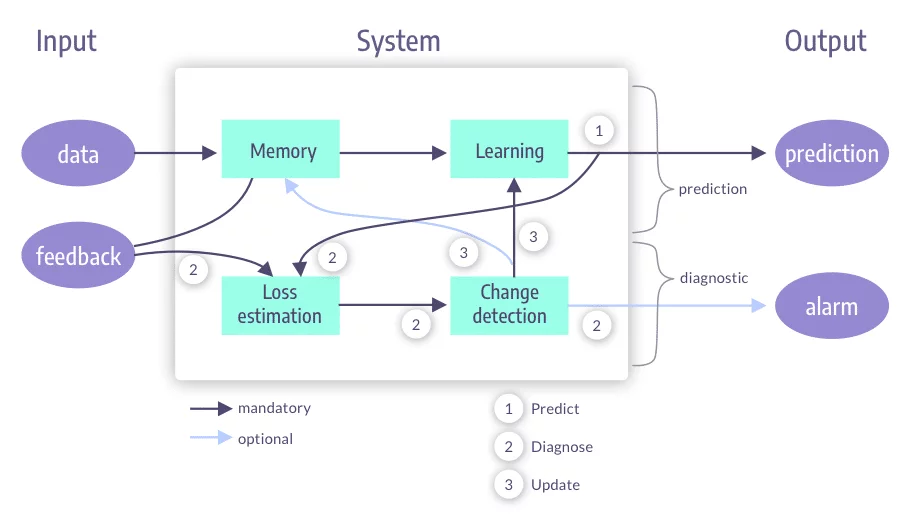
Model and data drift are like silent killers in the production environment. They can cause the model to make wrong predictions without even realizing it.
- Data Drift happens when the distribution of the input data changes. For example, customer preferences in a recommendation system might change seasonally, or market conditions might alter consumer behavior.
- Model Drift occurs when the relationship between the input data and predictions changes. For example, a stock market prediction model might become inaccurate as the financial landscape changes.
How to Detect Drift:
- Monitor Input Data: Check the statistical properties of incoming data over time (e.g., mean, standard deviation) to spot shifts.
- Track Predictions: Compare model outputs to actual results to identify discrepancies that could signal concept drift.
- Use drift detection algorithms like ADWIN or D2 that can automatically identify drift.
Secret Tip: Combine data and concept drift monitoring. If the data distribution changes, but the model continues to make accurate predictions, then data drift isn’t an issue. But if both are drifting, it’s time to retrain the model.
3. Automate Retraining Pipelines
The key to continuous training is automation. Retraining a model manually each time new data arrives is not only inefficient but also prone to errors. It needs a pipeline that can trigger retraining automatically when needed.
How to Automate:
- Automated Data Collection: Set up a system to automatically gather new data (e.g., daily logs, user interactions, sensor data).
- Automated Training: Use platforms like Kubeflow, MLflow, or TensorFlow Extended (TFX) to create retraining pipelines that can pick up new data and retrain the model on-demand.
- Version Control: Keep track of model versions, so it can roll back to a previous version if a new one performs poorly.
Secret Tip: Implement incremental learning to update models incrementally rather than retraining from scratch. This reduces training time and resource consumption.
4. Evaluate Model Performance with A/B Testing
Just because you’ve trained a new model doesn’t mean it’s automatically better. A/B testing is a great way to evaluate new models in production.
How to A/B Test:
- Split traffic between the current model (the control group) and the new model (the experiment group).
- Compare key performance metrics, such as user engagement or conversion rate, to evaluate the effectiveness of the new model.
- If the new model performs better, promote it to production; otherwise, debug and try again.
Secret Tip: Make sure to test models over a longer period to account for changes in external factors (e.g., seasonality, user behavior shifts).
5. Ensure Model Interpretability and Transparency
When continuously training models, especially in regulated industries (finance, healthcare), it’s essential to ensure the models are transparent and explainable.
Why It Matters:
- Compliance: In sectors like finance or healthcare, one may need to justify the model’s decisions for legal or ethical reasons.
- Trust: Users are more likely to trust a model that can explain why it made a certain decision.
How to Achieve Explainability:
- Use techniques like SHAP or LIME to understand model predictions.
- Track which features contribute most to predictions over time.
Secret Tip: For continuous training, ensure that model explainability is part of the monitoring setup. This way, when retraining, one can verify that the model’s decisions remain understandable.
6. Version Control and Rollback Mechanism
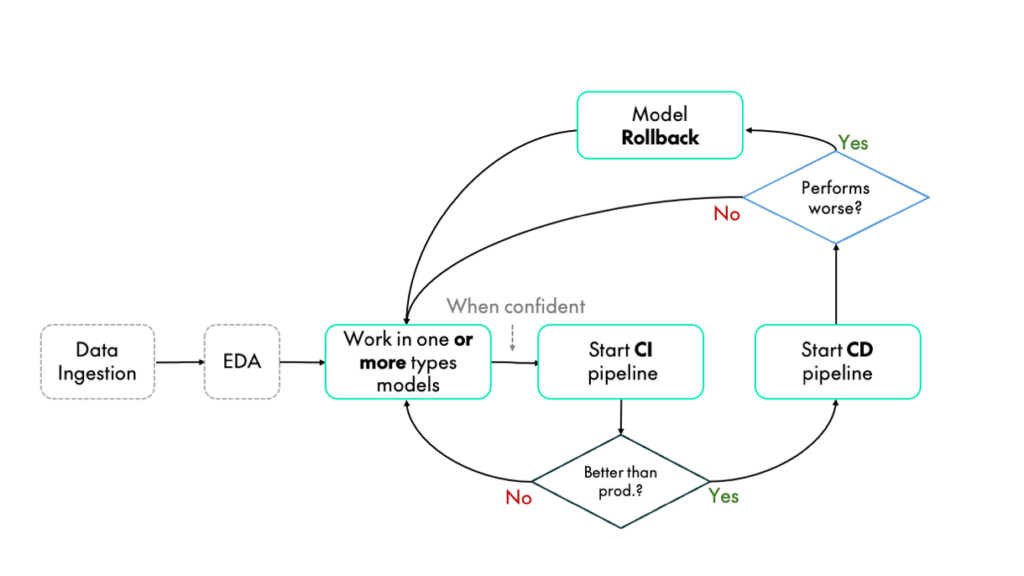
As the model evolves, you’ll want a way to track different versions and roll back to previous models if necessary.
How to Version Control:
- Model Versioning: Tools like MLflow and DVC (Data Version Control) allow to version both the models and the data they were trained on.
- Rollback Strategy: Ensures that it can easily deploy a previous model version if the current one underperforms.
Secret Tip: Always test new models in a staging environment before deploying to production to catch potential issues early.
Takeaways
Building a continuous ML training system in production is not just about updating models—it’s about ensuring that the models are always relevant, accurate, and aligned with real-world data and business objectives. By monitoring performance, detecting drift, automating pipelines, A/B testing, and ensuring explainability, it can create a robust system that helps the models stay effective long-term.
The secrets to success in continuous ML training lie in automation, real-time monitoring, and incremental improvements. When done right, it allows the models to continuously evolve, adapt, and deliver better results with minimal manual intervention—keeping the business ahead of the curve.
By following these practices, you’ll have a machine learning system that doesn’t just work in production, but thrives in it.
